安裝 R 環境 & IDE 安裝 R 環境
1 2 3 4 5 6 7 https://cran.r-project.org/ 下載對應的 OS 安裝檔 EX: Windows 1.Download R for Windows 2.install R for the first time 3.Download R 3.4.2 for Windows
安裝 R IDE
1 2 3 https://www.rstudio.com/products/rstudio/download/ 下載免費版本即可
安裝 Anaconda Python 1 2 3 4 5 6 7 8 https://www.anaconda.com/download/ 安裝 3.6 版本 Anaconda Python 其實類似組合包 就是 Python + 常用到的 Lib 一起下載 當然你也可以單純下載 Python 3.6 然後再找需要的 Lib 安裝 不過就會比較麻煩,常常某個 Lib 需要依賴其他 Lib 等等 所以建議直接安裝 Anaconda Python
安裝完可以打開 Anaconda Navigator
其中Spyder 是 Python 的 IDE
上方View->panes 可以自訂 IDE 的介面呈現
資料的預先處理 在機器學習之前,要將給機器的 Data 做預先處理的動作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 Get the Dataset Importing the Libraries Importing the Dataset Missing Data Categorical Data Splitting the Dataset into the Training set and Test set Feature Scaling Data Preprocessing Template A.下載 Dataset B.導入標準庫 C.導入 Dataset D.缺失 Data E.分類 Data F.將 Data 分為 Training set 和 Test set G.特徵縮放 H.Data 預處理模板
A.下載數據集 1 2 https://www.superdatascience.com/%E4%B8%8B%E8%BD%BD%E6%95%B0%E6%8D%AE%E9%9B%86/ https://zhuanlan.zhihu.com/p/25138563
首先開啟 data 檔案如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Country Age Salary Purchased France 44 72000 No Spain 27 48000 Yes Germany 30 54000 No Spain 38 61000 No Germany 40 Yes France 35 58000 Yes Spain 52000 No France 48 79000 Yes Germany 50 83000 No France 37 67000 Yes 假設這是某公司中,客戶的紀錄 分別代表此客戶的國家/年齡/薪水/是否購買過本公司的產品 所以我們的目的就是要透過 ML 來建立一個機器學習模型 預測新的客戶是否可能會購買本公司的產品
Step1: 機器學習模型都有一個自變量和應變量
例如在一個函數中,x 可以自由取值,所以稱為自變量(可以變化的量)
y 的值取決於 x ,所以稱為應變量(應其他量而變化的量)
以此例子來說
自變量 = 客戶的國家/年齡/薪水
應變量 = 客戶是否會購買本公司的產品 (結果)
Step2: 需要對 data 做預處理
B.導入標準庫 分別在 Python & R 中導入標準庫
在 Python 中導入標準庫,以下 3 種幾乎每次都會使用
打開 Spyder 填入
1 2 3 4 5 6 7 8 # numpy 念 /nΛm pi/,as 是縮寫的意思,之後就可以直接寫 np 而不是 numpy # matplotlib 是一個大的庫,我們只需要其中的 pyplot 就可以寫成 matplotlib.pyplot # 此庫主要用來畫圖 # 最後一個 pandas 用來導入 data 以及操作 data 使用 import numpy as np import matplotlib.pyplot as plt import pandas as pd
在 R 中導入標準庫,開啟 RStudio
1 2 3 4 5 6 7 在右下角 TAB 視窗選擇 packet,需要把以下 lib 打勾 datasets graphics grDevices methods stats utils
C.導入 Dataset 為了讓程式可以讀取要導入的檔案,需要先設定工作路徑
設定工作路徑有 2 種方式
1.右上角 File Explorer 中直接切換到 data 所放的位置
例如你的 csv 檔案放在 d:\dataset 中,那你就切到這個位置
2.直接將你的 python 檔案存在和 csv 同個位置
1 2 3 4 # 以下可以將 csv 導入 # 選取程式碼按下 ctrl + enter dataset = pd.read_csv('Data.csv')
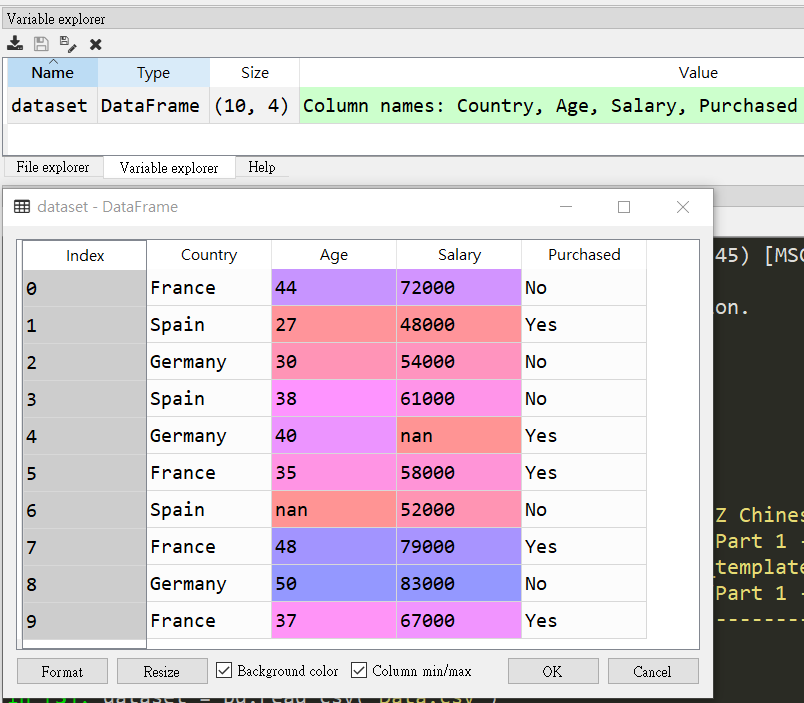
成功之後可以透過 variable explorer 看到導入狀況
注意 python 中行列由0 開始,但 R 由1開始
接下來加入以下程式
1 2 3 4 5 6 7 8 dataset = pd.read_csv('Data.csv') X = dataset.iloc[:, :-1].values # 自變量 y = dataset.iloc[:, 3].values # 應變量 iloc 表示要取出 Dataset 中的某行或某列 後面的括號表示 [橫,直] ,如果打 : 表示所有 例如: [:, :-1] 表示取所有橫,:-1 取所有直,但"不會"取最後一直 因為最後一直是應變量所以不取,.values 是取裡面的值
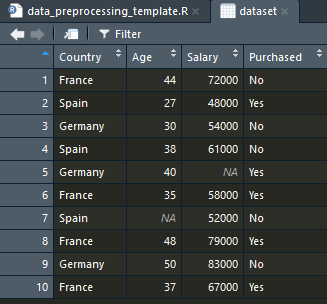
在 R 中導入 dataset
同樣先切換到 csv 目錄,但是還要按 more -> set as Working Directory
1 2 3 4 dataset = read.csv('Data.csv') ctrl + enter = 執行選取程式 ctrl shift + enter = 執行所有
可以看到由 1 開始
另外在 R 中不需要做取出自變量或應變量的動作
D.缺失 Data 在 dataset 中有時候會有缺失數據的情況發生
1 2 3 4 5 6 7 8 9 10 11 Country Age Salary Purchased France 44 72000 No Spain 27 48000 Yes Germany 30 54000 No Spain 38 61000 No Germany 40 Yes France 35 58000 Yes Spain 52000 No France 48 79000 Yes Germany 50 83000 No France 37 67000 Yes
此範例就有兩個缺失數據,最簡單的作法就是直接將兩列資料刪除
1 2 3 4 5 6 7 8 9 Country Age Salary Purchased France 44 72000 No Spain 27 48000 Yes Germany 30 54000 No Spain 38 61000 No France 35 58000 Yes France 48 79000 Yes Germany 50 83000 No France 37 67000 Yes
但風險是可能刪掉重要的資訊,另一種方式是取其他欄位的平均
以下是 python 計算平均的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # sklearn = scikit-learn,preprocessing 是其中一個子集庫 # Imputer 是 preprocessing 中的一個類別 from sklearn.preprocessing import Imputer imputer = Imputer(missing_values='NaN',strategy='mean',axis=0) imputer = imputer.fit(X[:,1:3]) X[:,1:3] = imputer.transform(X[:,1:3]) /* 可以在類別上面輸入 ctrl + i 會出現 help 頁面 第 1 參數表示,如何判斷為缺失數據,這邊指定只要是 'NaN (Not A Number)' 即為缺失數據 第 2 參數表示,用什麼策略處理此數據 - mean 平均 - median 中位數 - most_frequent 最常出現 第 3 參數表示,取"橫"或"直"來計算 - axis=0, then impute along columns. - axis=1, then impute along rows. */
這時候執行可能會遇到 ImportError: cannot import name NUMPY_MKL
解決如下,先下載以下檔案
1 2 https://www.lfd.uci.edu/~gohlke/pythonlibs/#numpy # numpy-1.13.3+mkl-cp36-cp36m-win_amd64.whl
關掉 Anaconda,重新以系統管理員身分啟動
啟動後左邊選Environments,按下 root 右邊三角形 -> Open Terminal
切到剛下載whl檔案的地方執行 pip install numpy-1.13.3+mkl-cp36-cp36m-win_amd64.whl
重新打開 Spyder 即可
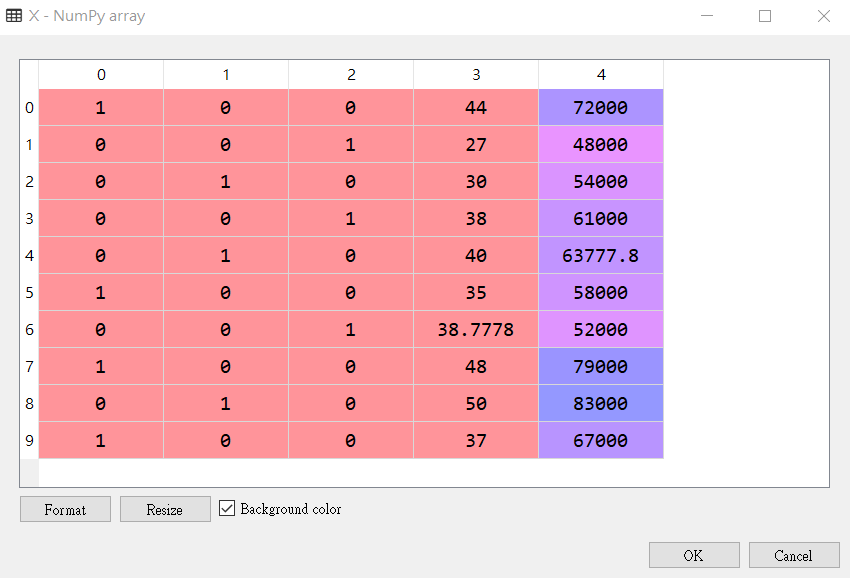
1 2 3 4 5 6 7 8 9 10 11 # X 執行如下 array([['France', 44.0, 72000.0], ['Spain', 27.0, 48000.0], ['Germany', 30.0, 54000.0], ['Spain', 38.0, 61000.0], ['Germany', 40.0, 63777.77777777778], ['France', 35.0, 58000.0], ['Spain', 38.77777777777778, 52000.0], ['France', 48.0, 79000.0], ['Germany', 50.0, 83000.0], ['France', 37.0, 67000.0]], dtype=object)
在 R 中處理缺失數據
1 2 dataset$Age[is.na(dataset$Age)] = mean(dataset$Age, na.rm = T) dataset$Salary[is.na(dataset$Salary)] = mean(dataset$Salary, na.rm = T)
在 R 中和常見程式寫法比較不同
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 dataset$Age 或 dataset$Age[] 這樣輸入會直接迭代出此陣列的 Age 數據,不用額外寫 loop [1] 44 27 30 38 40 35 NA 48 50 37 如果要取其中某個值可以直接寫下標,注意是從 0 開始 > dataset$Age[1] [1] 44 > dataset$Age[2] [1] 27 > dataset$Age[6] [1] 35 > dataset$Age[11] [1] NA 如果要判斷是不是 na 可以這樣寫 > dataset$Age[is.na(dataset$Age)] [1] NA > dataset$Age[!is.na(dataset$Age)] [1] 44 27 30 38 40 35 48 50 37 依序顯示陣列中的數值是否為 na > is.na(dataset$Age) [1] FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE mean() 是取平均值的意思 但如果我們輸入 mean(dataset$Age) 會變成 > mean(dataset$Age) [1] NA 因為如果陣列中其中一個元素為 na,取平均後就會變 na 所以要改為 mean(dataset$Age, na.rm = T) 也就是只要是 na 就 remove(rm) 的意思
E.分類 Data
目前我們的 dataset 有國家,年齡,薪水,是否購買
其中年齡和薪水是數字,但國家和購買不是
所以現在要想辦法把這些不是數字的轉為有意義的數字
以下是 Python 作法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from sklearn.preprocessing import LabelEncoder labelencoder_X = LabelEncoder() labelencoder_X.fit_transform(X[:,0]) 執行後出現 array([0, 2, 1, 2, 1, 0, 2, 0, 1, 0], dtype=int64) -> 對應國家 Country Age Salary Purchased 1 France 44.00000 72000.00 No 2 Spain 27.00000 48000.00 Yes 3 Germany 30.00000 54000.00 No 4 Spain 38.00000 61000.00 No 5 Germany 40.00000 63777.78 Yes 6 France 35.00000 58000.00 Yes 7 Spain 38.77778 52000.00 No 8 France 48.00000 79000.00 Yes 9 Germany 50.00000 83000.00 No 10 France 37.00000 67000.00 Yes 改為以下程式取代原本的 X from sklearn.preprocessing import LabelEncoder labelencoder_X = LabelEncoder() X[:,0] = labelencoder_X.fit_transform(X[:,0]) X 顯示如下 array([[0, 44.0, 72000.0], [2, 27.0, 48000.0], [1, 30.0, 54000.0], [2, 38.0, 61000.0], [1, 40.0, 63777.77777777778], [0, 35.0, 58000.0], [2, 38.77777777777778, 52000.0], [0, 48.0, 79000.0], [1, 50.0, 83000.0], [0, 37.0, 67000.0]], dtype=object)
不過這樣有個問題是,原本國家單純只是個名稱而已
如果換成數字後,就變成會有”大小”或”排序”的問題
所以這裡用另一個方法稱為”Dummy Encoding(虛擬編碼)”
1 2 3 4 5 6 7 8 9 10 11 France Spain Germany 1 0 0 0 1 0 0 0 1 0 1 0 0 0 1 1 0 0 0 1 0 1 0 0 0 0 1 1 0 0
這樣的好處是消除了排序的問題
以下是 python 的作法
1 2 3 4 5 6 7 8 from sklearn.preprocessing import LabelEncoder, OneHotEncoder labelencoder_X = LabelEncoder() X[:,0] = labelencoder_X.fit_transform(X[:,0]) onehotencoder = OneHotEncoder(categorical_features=[0]) X = onehotencoder.fit_transform(X).toarray() # categorical_features=[0] 裡面的 0,表示處理第 0 columns # 也就是國籍的部分
最後是將”是否購買”也轉為數字
1 2 3 4 5 6 7 8 from sklearn.preprocessing import LabelEncoder, OneHotEncoder labelencoder_X = LabelEncoder() X[:,0] = labelencoder_X.fit_transform(X[:,0]) onehotencoder = OneHotEncoder(categorical_features=[0]) X = onehotencoder.fit_transform(X).toarray() labelencoder_y = LabelEncoder() y = labelencoder_y.fit_transform(y)
以下是 R 的作法
在 R 裡面有分”有序因子”和”無序因子”
分別表示不同類別之間是否有”順序”的區別
在 R 中要看 HELP 說明按”F1”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 dataset$Country = factor(dataset$Country, levels = c('France', 'Spain', 'Germany'), labels = c(1,2,3)) # c 表示向量,執行完 dataset 變為 Country Age Salary Purchased 1 1 44.00000 72000.00 No 2 2 27.00000 48000.00 Yes 3 3 30.00000 54000.00 No 4 2 38.00000 61000.00 No 5 3 40.00000 63777.78 Yes 6 1 35.00000 58000.00 Yes 7 2 38.77778 52000.00 No 8 1 48.00000 79000.00 Yes 9 3 50.00000 83000.00 No 10 1 37.00000 67000.00 Yes # 同樣做法把"是否購買也轉為數字" dataset$Country = factor(dataset$Country, levels = c('France', 'Spain', 'Germany'), labels = c(1,2,3)) dataset$Purchased = factor(dataset$Purchased, levels = c('No','Yes'), labels = c(0,1)) # 變為以下數據 Country Age Salary Purchased 1 1 44.00000 72000.00 0 2 2 27.00000 48000.00 1 3 3 30.00000 54000.00 0 4 2 38.00000 61000.00 0 5 3 40.00000 63777.78 1 6 1 35.00000 58000.00 1 7 2 38.77778 52000.00 0 8 1 48.00000 79000.00 1 9 3 50.00000 83000.00 0 10 1 37.00000 67000.00 1