A.下載 Dataset B.導入標準庫 C.導入 Dataset D.缺失 Data E.分類 Data F.將 Data 分為 Training set 和 Test set G.特徵縮放 H.Data 預處理模板
所謂機器學習,就是讓機器知道數據之間的關係
並用學習到的結果,對新的資訊來做預測
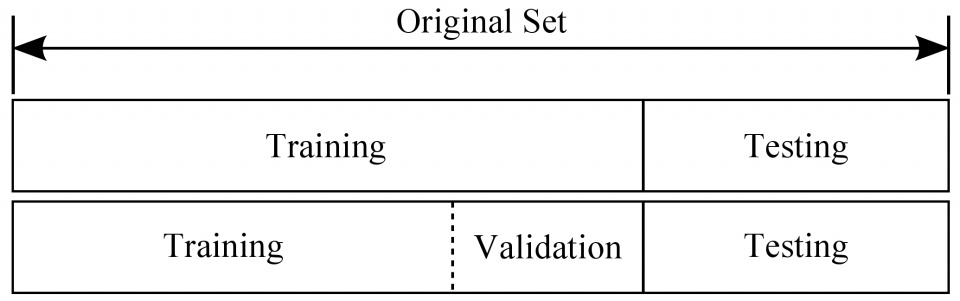
一般來說,當你拿到一組 dataset 之後
會把 dataset 分為 Training set 和 Test set
或是 Training set 和 Test set 和 validation set
不過一般會忽略 validation set
舉例來說你可能會拿到 100 筆 dataset 資料
那我們會把 100 筆中隨機拿 80 筆資料出來當 Training set
機器透過 Training set 會自己產生一個”模型”出來
最後再將剩下的 20 筆資料丟進此”模型”
來驗證此模型是否有好的預測能力
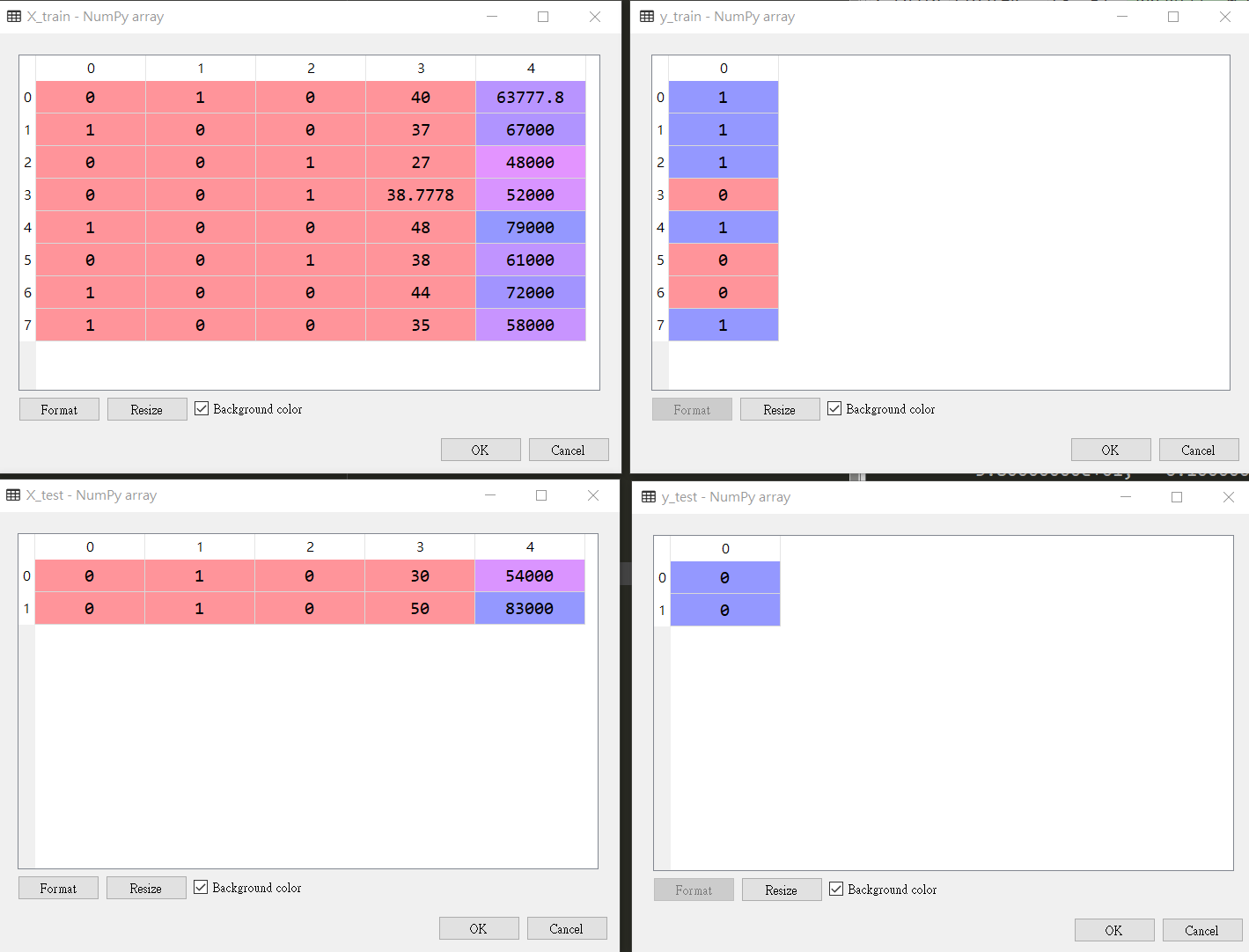
以下是 python 作法,目前我們已經有 2 個 dataset
分別是 X 和 y,所以將此 2 個 dataset 分別建立 Training set 和 Test set
所以最後會有 4 組資料
1 2 3
X -> X Training & X Test
y -> y Training & y Test
其中 X 屬於字變量,y 屬於應變量(結果)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
from sklearn.model_selection import train_test_split X_train,X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
/* train_test_split 第一個參數是 array 要傳入想要分割為 Training set 和 Test set 的 dataset 此處當然是傳入 X 和 y
test_size 參數表示你想要將 dataset 中,多少比例變為 Test set 剛剛說過如果 100 筆資料,你想要 20 筆變成 Test set 那 test_size 就輸入 0.20,所以此參數是個比例的意思,藉由 0.0 - 1.0 之間 通常不會將 Test set 分配超過 0.50 ,這樣會導致 Training set 太少
train_size 參數就可以省略不寫,因為你設定好 Test set 比率後 就知道 Training set 比率是多少,由此可知為 0.80
random_state 設定如何從 dataset 中取資料分配到 Training set 和 Test set 如果 = 0 表示固定 */
# Importing the libraries import numpy as np import matplotlib.pyplot as plt import pandas as pd
# Importing the dataset dataset = pd.read_csv('Data.csv') X = dataset.iloc[:, :-1].values y = dataset.iloc[:, 3].values
# Taking care of missing data from sklearn.preprocessing import Imputer imputer = Imputer(missing_values='NaN',strategy='mean',axis=0).fit(X[:,1:3]) X[:,1:3] = imputer.transform(X[:,1:3])
# Encodig catagorical data from sklearn.preprocessing import LabelEncoder, OneHotEncoder labelencoder_X = LabelEncoder() X[:,0] = labelencoder_X.fit_transform(X[:,0]) onehotencoder = OneHotEncoder(categorical_features=[0]) X = onehotencoder.fit_transform(X).toarray() labelencoder_y = LabelEncoder() y = labelencoder_y.fit_transform(y)
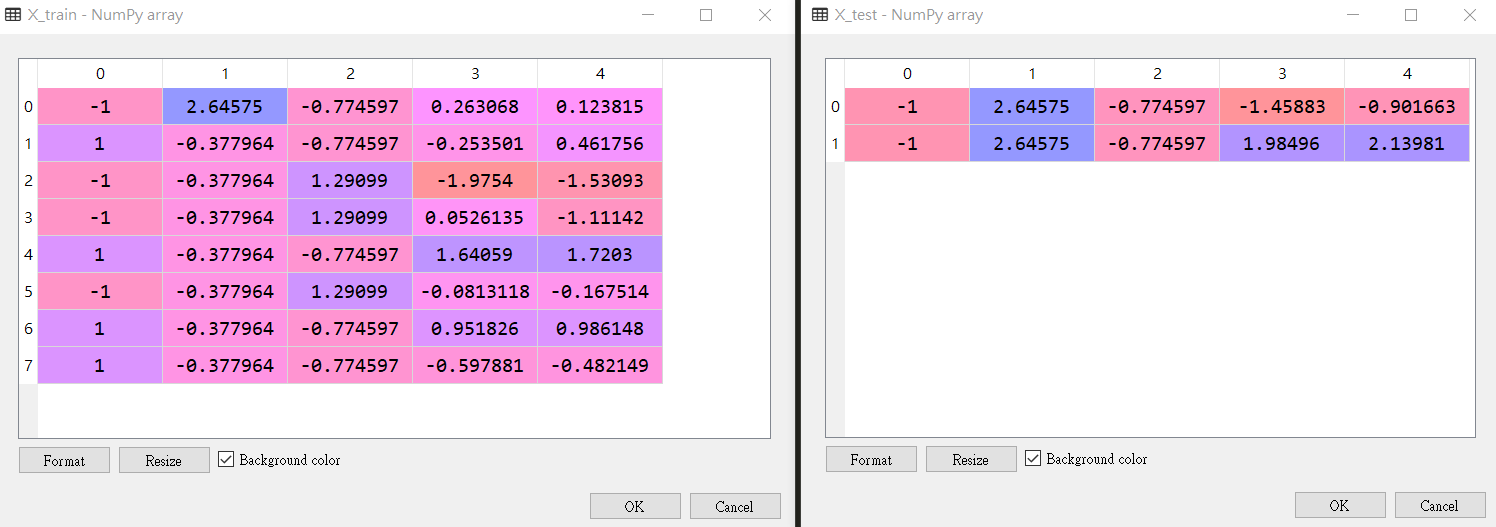
# Splitting the dataset into the Training set and Test set from sklearn.model_selection import train_test_split X_train,X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
# Importing the libraries import numpy as np import matplotlib.pyplot as plt import pandas as pd
# Importing the dataset dataset = pd.read_csv('Data.csv') X = dataset.iloc[:, :-1].values y = dataset.iloc[:, 3].values
# Splitting the dataset into the Training set and Test set from sklearn.model_selection import train_test_split X_train,X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
# Splitting the dataset into the Training set and Test set #install.packages('caTools') library(caTools) set.seed(123) split = sample.split(dataset$Purchased, SplitRatio = 0.8) training_set = subset(dataset, split == TRUE ) test_set = subset(dataset, split == FALSE )
# Importing the dataset dataset = read.csv('Data.csv') #dataset = dataset[,2:3]
# Splitting the dataset into the Training set and Test set #install.packages('caTools') library(caTools) set.seed(123) split = sample.split(dataset$Purchased, SplitRatio = 0.8) training_set = subset(dataset, split == TRUE ) test_set = subset(dataset, split == FALSE )